
Photo by Tudor Baciu
NoTTL - A new caching concept?
- June 21, 2021
- Recommended, Innovation, Web, Caching, Software architecture, Nottl
Table of Contents
There is an old joke in IT that goes “The 2 hardest things in programming is Naming, Caching, and off by one error’s”. I’ve often said there is another one: the first-hit performance problem.
I’ve worked with several websites where everything is fine when the cache is there, but then it expires and you’re left with dreadful 3-5 second load times at best, and sometimes a lot more. Users leave the site, google gives you a bad score, and as a result your SEO rank drop, adding to the downward spiral.
The first-hit problem
When the cache has expired on a page you often need backend processing (unless you run Hugo like me) to build the page a-new. The speed of that process depends a lot on what kind of framework you’ve got, and how much computing power you have available. At some point, you hit a bottleneck, which is often going to be your database, and you start seeing slower page loads and there really isn’t much you can do about it. Sure you can start adding in-memory cache like Redis, or Memcached, maybe use some document storage for parts of your page like the footer or header, but these are all just drops in the ocean. The real issue is that you have dynamic content and you want your users to see it when new content becomes available.
A second more sinister problem can occur. Cache race conditions. These happen when multiple clients try to load the same page before a cache becomes available. The result is often multiple processing of the page, and while in theory the first person hitting a page with expired cache should trigger the creation of new cache - and do the heavy processing to get the dynamic content - every user hitting the page before a cache is generated will trigger the processing. This can cause a lot of resource problems on the servers if enough people do it, and these can be especially tricky to figure out. Additionally, if you’re paying per request or per Mb of data this also increases your server costs.
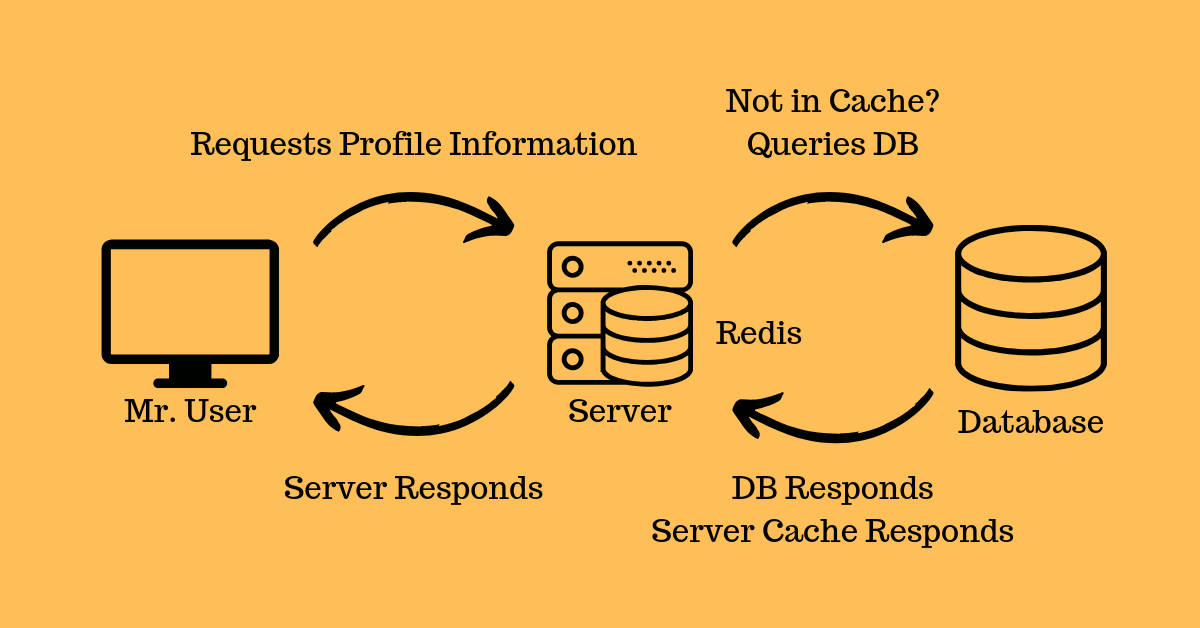
The TTL strategy flaws
The general idea of TTL - Time to Live - is to define a timeframe in which the cache is “current”, which can be anything from a few minutes to several hours. Depending on your framework, this is usually either fixed or semi configurable for the whole application and requires careful consideration when configuring it to deal with some of the potential issues listed above. TTL is used to set cache expiration for backend caches such as Redis or Memcached, and for frontend (also known as response caches or HTML accelerators) caches. The TTL strategy is applied to so many systems, that we’ve come to think of it as the default way of implementing caching. However, several problems with this strategy can occur. Some examples are:
- It can provoke race conditions
- Servers can get flooded with requests when the cache expires
- Performance bottlenecks
- Request timeouts
The technical issues all have mitigation fixes, but none of those fixes will eliminate the problems. Race conditions can be handled by implementing a so-called semaphore lock, but this will likely cause more timeouts. Graceful cache handling such as serving stale caches until the “first-hit” request has created a new cache can help deal with most of the above but requires a lot of careful planning because applying it to the backend caches is exceptionally complicated. For this reason, most applications using a graceful cache strategy only implement it for their frontend cache, and it can be a viable strategy if your frontend cache software allows you to serve stale caches to everyone - including the first-hit requester - while handling the backend requests independently from the client requests.
The idea of TTL is fundamentally flawed because it builds on the idea that the requester triggers the cache build. When content updates it’s usually because editors, integrations or some other trigger occurs. When we know this, why would we need to set an expiration? The simple answer is that TTL is easy, and understanding all the instances in which cache should be updated is complicated.
Event-driven caching
Events are driving the modern web. AWS makes extensive use of event-driven architecture, not only for Serverless applications but for just about anything. The simplest example of an application using event-driven architecture is one where a video file is uploaded to an S3 bucket and is automatically encoded using event triggers.
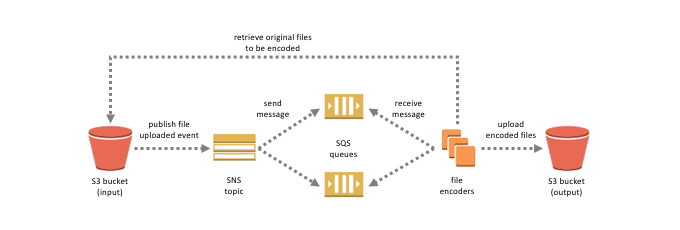
An event-driven cache implementation is most often used for cache expiration. A common pattern is to use cache tagging, effectively marking all your cache with generalized taxonomy, allowing you to expire all caches with a specific cache tag without knowing the exact cache key. Redis and Varnish are two examples of caching software that supports cache tags natively, but it can be implemented for Cloudfront and Memcached as well, though it may require a custom implementation to keep track of which tags a cache key has.
An asynchronous event-driven cache allows for the implementation of graceful caching by delegating the cache generation to a different process and simply returning a stale cache to the original request. Now all you have to do is keep a semaphore lock, to keep track of cache starts, and you’ve pretty much got your graceful cache. But I already know when I need to generate a new cache, so why would I ever need a graceful cache?
NoTTL
NoTTL is an idea born of all of the above considerations. I wanted to address the issues of “first-hit”, and I’ve never been entirely comfortable with TTL, but I wasn’t able to articulate my discomfort. I was working on an application - an API - when it occurred to me that I always knew when data was being added, changed, or deleted. I was already using cache tags, so why couldn’t I use the same strategy to generate the new caches? Granted, the application was relatively simple, and triggering asynchronous requests to my own API endpoints was fairly trivial, but the concept held up. When the API went into the testing phase the response times during maximum loads never went above 30ms even though new content was being added during the load test, prompting a major reduction of server resources. Response times stayed the same, and even at a 80% reduction in resources (the minimum achievable to comply with availability requirements) no change in response times were found.
I believe we need to think very differently about caching and create a new norm - NoTTL. TTL generates many problems and all of these can only be mitigated. We’ve come up with some great mitigation strategies, but it feels backward to me. So I’m going to work on NoTTL libraries, cache implementations, and examples of how you can implement them during this year.
Related Posts

Hugo: A flat file CMS.
- April 20, 2021
- Recommended, Innovation, Framework, Gohugo, Flat file, Web, Cms
As a developer, I’ve had plenty of experience setting up sites for clients, but when it comes to my own site, I often can’t be bothered. WordPress …
Read More
Hugo: Two years with a flat-file serverless website
- May 14, 2023
- Recommended, Innovation, Framework, Gohugo, Flat file, Web, Cms
In May 2021, I was fed up with my website. It was nothing more than a business card with contact information, and it cost me $20 a month to host it.
Read More
Why you should be using Go-Task
- March 3, 2023
- Recommended, Web, Tools, Innovation
In today’s tooltip I’ll be showcasing go-task. It’s a tool designed to make executing terminal commands or even lists of commands needed for …
Read More