
Photo by Stormseeker
RAG Isn't Dead
Table of Contents
The idea that RAG is dead has been spreading like wildfire, but over and over again I see people lay out their proof and the mistakes are glaring. More importantly, high profile people in the AI business get their words twisted and drafted into the argument. Case in point, this X post by Boris Cherny
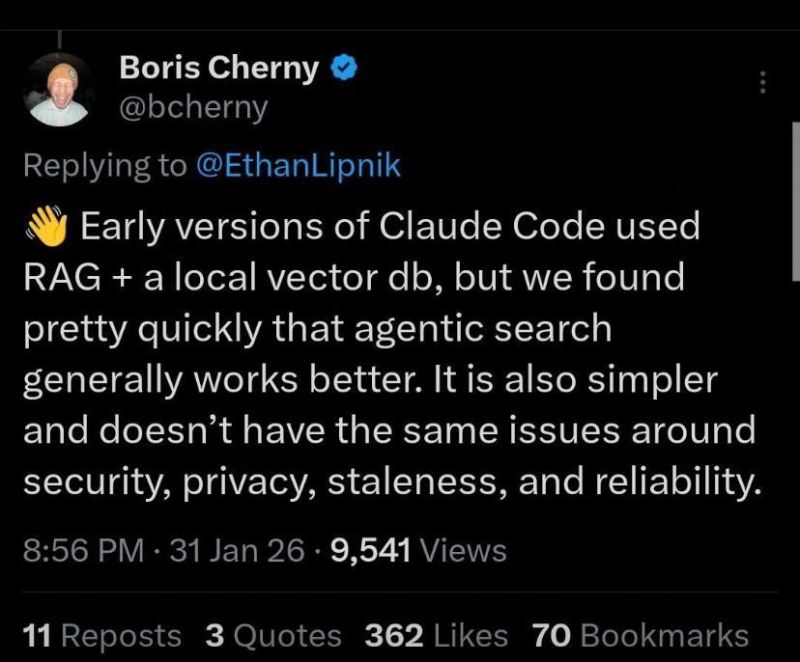
Let’s be clear about what Cherny is saying here. For Claude Code specifically, agentic search “worked better”. There are many reasons why that could be the case, but “RAG is DEAD” isn’t one of them. Yet people are already picking sides, and thinking of this as an either or situation. But it isn’t. Most of the time the question is WHEN to use RAG, and not IF. But grasping that nuance requires more than a surface-level knowledge of what RAG actually is and how it works.
So let’s see if we can’t fix that.
What people think RAG is
There are about a thousand tutorials out there giving you the naive version of how RAG works, and if you’re reading this, you probably read at least 3 of them. I know I did when I was starting out. So here’s the abridged version:
Chunk your text. Embed the chunks. Search by similarity. Take the top 5 results. Stuff them into a prompt. Done.
Except it isn’t.
You’ve probably started with a fixed length chunking - 500 characters sounds about right - then tried a recursive chunking strategy with some overlap. You picked an embedding model, wired it into the search, and connected your prompt. It looked fine.
For a while.
Then more and more cases crept in where the answers were wrong, or incomplete, or subtly off in ways that were hard to pin down.
So you tried smaller chunks. Maybe a sentence-level chunker. The reasoning felt sound: fewer characters per chunk, more precise results. But the results didn’t improve the way you expected, and now you’re stuck. You have a RAG pipeline. It followed the tutorial. So why doesn’t it work?
The answer is that every step in that pipeline carries assumptions most tutorials never mention.
Why naive RAG fails
Try taking an article, and cutting it into chunks of an arbitrary size. Try this article if you like. Now try reading a random chunk. Not very helpful, is it?
This is exactly the problem the LLM runs into when you apply a chunking strategy with no respect for the content you are chunking. What you get is content without coherence. Apply this to 100 articles, search for the mention of specific keywords, and the problem only gets worse. For most reasoning, coherence matters, because to give an exact answer you need to understand the full picture.
The same applies to LLMs.
They are better than most people at filling in gaps, but it isn’t going to cut it if you’re trying to answer a specific question. Couple this with the fact that similarity isn’t the same as relevance, and the quality of your results are going to degrade.
The natural instinct is to reach for more advanced chunking strategies. Paragraph or structure based chunking, or LLM guided chunking, but using an advanced strategy doesn’t equal better results. In the recently published research paper Beyond Chunk-Then-Embed: A Comprehensive Taxonomy and Evaluation of Document Chunking Strategies for Information Retrieval, you can read - in the conclusion - that findings show that optimal chunking strategies are task-dependent.
The findings are counterintuitive. For standard retrieval tasks, simple structure-based chunking actually beats the fancy LLM-guided approaches. But flip to in-document retrieval and the pattern reverses.
Your search shouldn’t be a single shot, one-size fits all. We need to know what documents are relevant, and then search those documents with a different method, one which preserves coherence.
RAG done right: lessons from building
Before I show you what I built, it’s worth clarifying what RAG actually means, because the definition has gotten muddied.
RAG is the method through which the LLM gathers enough context to be able to answer a query. Regardless of whether or not you use embedded search, whenever you retrieve something and stuff it into a prompt to improve the output of the LLM, you’re doing RAG. It’s retrieval to augment generation. Embedding and embedded search are separate operations that have become almost synonymous with generative AI, but they’re just one form of RAG.
I recently sat down to rethink my own RAG pipeline. One of my system’s core capabilities is web retrieval, for injecting context on a subject into the prompt. This has context impact, and while a 1,500 token article might be fine, a 15,000 token research paper is more of a problem. The concern is both the attention problem - also known as context rot - and the limited size of local models context windows.
So the question becomes: how do you give the LLM access to a full research paper without actually putting the full research paper in the prompt?
The solution is to limit the context injected into the prompt, while adding the capability to use semantic search on it. The result was a web_fetch tool which looks something like this:
web_fetch(input: {url: string, refresh: boolean}) {
// Check if the url is in local storage first (because we store it)
// Fetch using playwright browser if we don't.
// Generate list of section in the article.
// Summarize article using LLM, including section by section concise summaries.
// Attach section list - it's an index or ToC.
// Store and Embed the article using a structured data chunking strategy (paragraph)
// Return the full summary + relevant metadata, which includes an articleId from storage.
}
I now have a summary, and an index card to input into my prompt. With this the LLM will know what sections the article contains, and have an idea what’s in them. The next step is to give it some additional tools, to inspect the article further. I’ll skip the embedded search tool, because you already know what that looks like, and jump directly to the point of having the index in the summary. A section retrieval tool:
web_recall_section(input: {articleId: string, header: string}) {
// Load the article from the id
// Generate a list of sections from the content.
// Return matched section.
}
It’s that simple. Now, the LLM can both query using semantic search, and retrieve full sections for a coherent understanding of what the context of those random chunks from before actually means. Where the heavy lifting is done, in both cases, is in the section generation. Articles and research papers are structured content, and usually - not always - contain headers. I convert all the html to markdown before parsing, because I’m storing it in markdown. The process of generating sections looks something like this:
parseMarkdownSections(markdown: string) {
// Split into lines
// Find markdown headings (## ### etc.)
// Split into flat segments: { depth, header, contentLines }
// Normalize depths so the shallowest heading becomes depth 1. Depth 0 is the title.
// Build nested tree using a stack. Because headings are sometimes nested (h2, h3, etc)
// Build a path through headings, to show placement depth when presented in flat array. Makes it easier to retrieve later.
}
findSections(header: string,
sections: MarkdownSection[],
ancestors: string[],
results: SectionMatch[],
) {
// Loop through sections until we find the header
// Build Section from it and its children, recursively
}
I’ve created a gist, where you can see the full codefile with all the utils i use for generating sections, and retrieving them.
The result of this approach is that my 15000 token research paper is now ~1000 tokens of summary, index, and metadata. With the search and section tools the LLM can now retrieve context relevant to my questions, and doesn’t need to keep the full research paper in its prompt, causing both context-rot and context size issues.
Key insight: You don’t need the full content to make a good enough starting summary. The summary is a starting point, not the final product. It’s a tool you can leverage to both cut a 15000 token context down to 1000 tokens of relevant information, and give the LLM a way to dive deeper into the meat of the context when it needs to.
MCP is just RAG
I’ve seen people saying MCPs will replace RAG enough that I need to clarify something.
Most MCPs are a protocol layer for connecting tools and data sources to LLMs. When an MCP server retrieves context to inject into a prompt, that’s RAG. The protocol changed, the principle didn’t. When you use an MCP, you’re adding another RAG pipeline, not replacing RAG with something else. This is the nuance that’s important to understand, because everything in this article builds on that. All the principles I just laid out, and are laid out in the research still apply.
The optimal chunking strategy IS task dependent. Single-shot approaches aren’t always enough. We still need to know what documents are relevant, not just the random chunks. Context limits and Context-Rot are still concerns you need to care about.
The biggest win of MCPs is that they make a lot of the hard decisions for you. The MCP knows its knowledge domain, and knows how best to apply RAG to it. This means we can separate that concern away from our application, and only consider how to wire the MCP into our prompt.
Be warned though: While some MCPs work to protect your LLM’s context, many don’t. They subscribed to the idea that a bigger context window means they can give you more context, without considering context-rot or how this applies to models with smaller context windows.
The real problem isn’t the technology
The problem was surface-level understanding of a subject that goes far beyond a few lines of code and an embedding model. Retrieval Augmented Generation requires a nuanced approach, not a single-shot solution, to work reliably. There are a lot of factors to consider. What kind of content are you working with? What are you trying to achieve? Where is the data coming from? and much more.
What most RAG tutorials do is try to boil RAG down to choosing a chunking strategy and an embedding model. This is simply incomplete, and the lack of nuance sets people up for failure. In my opinion this is why we’re seeing so many people declare “RAG is DEAD!” on social media, and in the same breath say “MCP is the future” or “Boris Cherny says so!”
What I’ve shown you are examples of where naive pipelines fail, and why. You’ve also seen RAG is more than an embedding pipeline, and what Claude Code is doing - according to Boris Cherny’s own words - is still considered RAG. Working on a RAG pipeline requires an understanding of how the data is structured, and how that affects your approach to RAG. Research exists to guide us, but it takes more than reading a summary.
RAG isn’t dead, and it won’t die anytime soon either. Without it, Claude Code wouldn’t be able to read or edit files. Without it ChatGPT wouldn’t be able to summarize the RAG tutorial you couldn’t hold your attention on long enough, to realize the author did actually tell you this was the basic approach. Not an exhaustive instruction manual.
RAG isn’t dead. It’s a fundamental principle making Agentic AI possible.
Related Posts

The AI Act and Executive Orders
- January 21, 2025
- Recommended, Artificial intelligence, Leadership, Innovation, Privacy
On January 20th, 2025, President Trump revoked Executive Order 14110, also known as the Executive Order on Artificial Intelligence. This order was the most …
Read More
I'm NOT like you. I'm an Engineer
- January 30, 2023
- Recommended, Leadership, Chatgpt, Blockchain, Software engineering, Artificial intelligence
Distributed Cloud, Artificial Intelligence, Blockchain, Quantum Computing, ChatGPT. I know all the buzzwords and the challenges they hide.
Read More
3 Reasons Scrum is failing you
- February 13, 2023
- Recommended, Agile, Scrum, Leadership, Management
Scrum fails in a lot of businesses. Most don’t realize it, and the rest accept it as an industry standard they can’t avoid. Here are three reasons why Scrum …
Read More